
When AI Characters Start to Feel Alive: Lipsync, Expression, and the Promise of Immersive Interaction
2026. 2. 10.
High-quality conversation is only one component of an immersive AI characters. Equally important is whether the character’s facial motion aligns with its speech. When language sounds intelligent but facial movement is rigid—or lip synchronization is even slightly misaligned—users perceive the inconsistency immediately, undermining trust and immersion.
At Genies, we are building an audio-to-facial-motion system that converts raw speech into time-aligned blendshape controls for lip synchronization and facial expression. The core objective is to generate coherent facial motion directly from audio, enabling performances that feel continuous and unified rather than composited from independent components. This post explains why this matters, how our approach differs from traditional pipelines, how audio→motion works at a conceptual level, how we scaled data without prohibitive annotation costs, and what we’re seeing in early results.
What Traditional Methods Fall Short
Traditional facial motion generation pipelines typically rely on viseme-based lipsync—mapping phonemes to discrete mouth poses—combined with manually authored or keyframed facial expressions. These methods are robust and interpretable, but they often feel robotic:
Lipsync accuracy and smoothness: Discrete viseme lookups and hand-tuned coarticulation frequently produce stepwise, temporally unstable mouth motion, failing to capture brief closures (e.g., /p/, /b/) and rapid vowel transitions—less accurate and less smooth than continuous, audio-conditioned prediction.
Expression–speech decoupling: Expressions are authored on a separate track, so brow/cheek/jaw dynamics are not conditioned on speech timing or prosody. The result is out-of-phase, global expressions that don’t evolve with syllables, stress, or emphasis.
For AI characters, the result is a perceptual gap: the avatar sounds human but doesn’t behave like a human. Users notice that instantly.
Our Approach

Fig. 1: dataflow diagram showing audio feeding a generator that outputs blendshapes
As illustrated in Fig. 1, our model maps audio directly to a time series of facial blendshape values, jointly modeling lipsync and expressive facial motion to preserve natural co-articulation. We find that training on well-filtered, emotionally rich data leads to more realistic and expressive facial motion, enabled by high-quality supervision data through AI-assisted facial-motion extraction and human-in-the-loop filtering. The model is optimized for low-latency and stable inference, making it suitable for real-time deployment scenarios.
Results: higher quality lipsync and expression
We first present quantitative results comparing Genies Facial Motion model against NVIDIA Audio2Face and a strong Open-Source SOTA baseline on our in-house evaluation dataset. Later, we provide qualitative examples to showcase our model results.
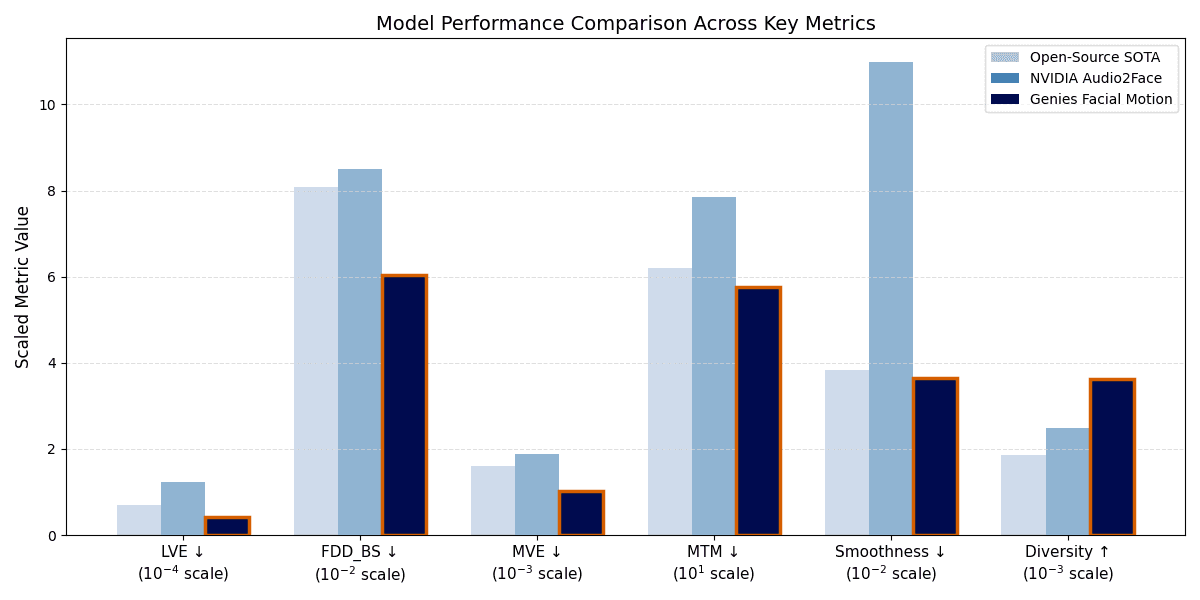
Fig. 2: This bar chart illustrates the performance of three models—Open-Source SOTA, NVIDIA Audio2Face, and our In-House Genies Facial Motion model—across six distinct metrics. The best performance model is highlighted by orange outline, notice our In-House model achieved best result across all metrics.
Metrics Definition:
Lipsync accuracy (LVE): Measures the precision of mouth vertices against ground truth, ensuring accurate lipsync.
Upper-Face Dynamics (FDD_BS): Quantifies how well the model captures subtle upper-facial expressions at the blendshape level. (e.g., raising eyebrows).
Global Accuracy (MVE): The mean Euclidean distance across all face vertices.
Temporal Sync (MTM): Measures the synchronization of motion over time; lower scores indicate tighter audio-visual alignment.
Naturalness (Smoothness, Diversity): Smoothness penalizes jitter for more natural motion, while Diversity rewards dynamic variance to prevent "robotic" or flat expressions.
Quantitative Evaluation: as shown in Fig. 2, Genies Facial Motion model demonstrates superior quantitative performance across all key metrics. Most notably, Genies Facial Motion achieves a 65% reduction in Lip Vertex Error (LVE) relative to NVIDIA Audio2Face, and a 39% reduction compared to the Open-Source SOTA baseline, indicating substantially higher lipsync precision.
Beyond lip accuracy, our model captures facial nuances more faithfully. We observe a 29% improvement in upper-face dynamics (FDD_BS) and a 26% reduction in temporal misalignment (MTM) compared to NVIDIA Audio2Face. Crucially, our model achieves this precision without sacrificing expressiveness: it delivers motion that is simultaneously smoother and up to 94% greater diversity.
Qualitative Evaluation: we focus evaluation on lipsync quality by comparing with one of the best open-source model. All videos shown below are development-stage demos and do not represent the final product. We note for all comparison videos, we use the same audio, the same rig, identical render settings.
First we provide a clip in which the avatar speaks an entire paragraph with our model’s lipsync output. Notice facial expression variations in our model follow the natural rhythm of speech with noticeably smoother temporal consistency and reduced jitter compared to the open source model.
Further, we provide 90% speed clips to articulate the difference of lipsync results:
“So technically” — the “so” syllable
Genies Facial Motion produces a stable lip purse and rounding, characterized by higher mouth-pucker amplitude and sustained duration. In contrast, the Open-Source SOTA exhibits lower amplitude and reduced temporal stability.
“Romance”
”ro” shaping: sustained lip rounding/protrusion and stable aperture, then a clean release into the next syllable.”; Open-Source SOTA remains flatter and wider the whole time.
Bilabial closure (/m/): complete seal before vowel onset; the Open-Source SOTA shows partial closure only.
“Love lives among the braingoo” — complex phrase
/v/ in “love”, “lives”: maintains lower-lip/upper-teeth contact with clean friction, avoiding smearing or premature release.
/m/ in “among”: achieves complete bilabial closure followed by a clean, timely release into the vowel.
/b/ in “braingoo”: produces a crisp closure and burst onset with a clear post-burst opening.
“goo”: demonstrates a rounded, forward-protruding mouth shape with smooth transitions and improved temporal alignment compared to the Open-Source SOTA.
In contrast, the Open-Source SOTA model generally fails to form sufficiently rounded or forward-protruding lip shapes and often leaves the mouth partially open, resulting in weaker articulation and less realistic motion.
Summary
Across all evaluated phrases, Genies Facial Motion consistently demonstrates superior articulatory precision and temporal stability compared to the Open-Source SOTA baseline. It produces greater lip rounding and protrusion during vowels (as in “so” and “ro”), complete bilabial closures for consonants like /m/ and /b/, and accurate lower-lip/upper-teeth contact for /v/. Transitions between these shapes remain smooth and well-timed, maintaining consistent aperture and alignment with the audio.
Beyond lipsync, the facial expression variations in our model follow the rhythm and emphasis of speech with smoother temporal consistency and reduced jitter, resulting in more natural, lifelike motion.
In contrast, the Open-Source SOTA often shows flatter, under-rounded lip shapes, partial closures, weaker synchrony, and visible jitter, leading to less expressive and less believable animation overall.
Looking ahead: emotion conditioning and personalization
Our next milestones focus on:
Personalized motion styles: People laugh, nod, and emphasize differently. We’re exploring lightweight style tokens and identity-aware layers so each character—and each user—can have a distinct performance signature.
Multimodal generation: Gradually expanding toward all-in-one generation that includes facial motion and body gestures. We’ll share progress and lessons learned in future posts.
Conclusion
Believable AI characters require more than strong language models; they depend on facial motion that is temporally coherent, expressive, and tightly coupled to audio. Genies’ audio-to-facial-motion approach prioritizes unified motion generation, supported by scalable data curation that avoids prohibitive manual annotation costs. Early results show improved lipsync over a strong Open-Source SOTA baseline, with promising expression variation, and stable, low-latency real-time playback—foundations for immersion and user trust.
If you are building AI characters, engines, or tools and want to discuss techniques or evaluate integrations, get in touch. We will continue sharing progress on emotion conditioning, personalization, and unified face-and-body performance in upcoming tech blogs.