
PERSONAS ARE THE NEW INTERFACE FOR AI. GENIES IS THE LAYER.
If you're building an AI product and want it to have a face, a personality, and a presence users actually come back to, talk to us about our character system.

For the last few years, AI has lived in two places. A text box and a voice stream. You type, it answers. You talk, it talks back. That's it. No presence, no body, nothing to look at, nothing that looks back.
That's fine for a tool. It's not enough for an interface.
AI can't just exist in a chat bubble. Every website, app, game, and brand is about to have an AI persona attached to it. Agents, assistants, companions, NPCs, brand reps, customer support, tutors, coaches, idols, influencers. The text box and the voice stream cannot carry that load. You can build a workflow with a chat input. You cannot build a relationship with one.
We spent five years and roughly $100M building the visual and embodiment layer for AI. This is why, and how.
A Face Is How Trust Gets Built

Humans are wired to read faces. Before language, before logic, we evolved to look at another being's eyes, mouth, and expression to decide whether to trust it. That circuitry does not turn off when the entity on the other side is artificial. It runs whether you want it to or not.
This is the part most AI products have ignored. A chat box is anonymous. A voice without a face is disembodied. Both demand that the user do all the work of imagining a presence on the other end, and most users will not. They engage transactionally, get their answer, and leave.
A face changes the math. The moment there is a character to look at, the user is no longer talking to a system. They are talking to someone. Persona stops being an abstract product decision and becomes something the user can see, recognize, and form a relationship with. Consistency of identity across sessions. Expression that responds to what the user is feeling. Gaze that lands when it should. Micro reactions that signal listening. These are not cosmetic. They are the substrate of trust.
Engagement follows trust. People come back to characters they recognize. They stay in conversations where they feel seen. They tolerate friction, ambiguity, and even mistakes from an entity that has a face, in a way they never will from a blank input field. Every consumer category that has tried to build emotional engagement around a chat input has hit the same wall. There's no one on the other end. The face is what changes that.
This is also why persona is the moat. Models commoditize. Voices commoditize. The underlying intelligence will eventually be a utility you swap between providers. What does not commoditize is a character a user has spent time with, knows the look of, and trusts. That relationship sits at the application layer, not the model layer. The face is what makes it durable.
Why a Character System, and Why Video Won't Get You There

If you're building the visual layer for AI today, there are two paths. A real-time character rig system, or video generation. They are not interchangeable. They produce different products with different economics, and the choice locks you in for years.
Video generation looks like the easy path. The server renders pixels, streams them down, every frame freshly computed by a model. It ships faster. You don't have to build a runtime. You don't have to maintain SDKs across iOS, Android, Web, desktop, and game engines. You don't need specialized rigging and runtime engineering talent in-house.
The photorealism ceiling is genuinely higher than what a rig can produce today, and the expressive quality of current video models is already good. For some products, that's the right call. Pre product-market fit, validating whether the visual layer drives retention before making a platform bet. Low character count that isn't going to scale. Asynchronous interaction where users tolerate a few seconds of latency. A photorealistic human as the value proposition. In those cases, video is the right tool.
It is the wrong tool for AI personas at scale.
The first problem is latency. Video generation cannot hold a real-time back-and-forth. Every frame is a server call, every response is a generation, and the gap between you speaking and the character reacting is long enough that the illusion of a conversation breaks. A face that responds a beat late stops feeling like a presence and starts feeling like a chatbot with a costume on. Real-time is not a nice-to-have for an AI persona. It is the entire reason you put a face on it.
The second problem is cost. Video generation is pixel output, and pixels are expensive. Every user, every session, every frame burns GPU on the server. There is no path to pushing the render to the client, which means costs scale linearly with usage and never get better. Unit economics that work at ten thousand users will bury you at ten million. For anything aimed at consumer scale, this is fatal math.
The third problem is identity drift. Generative video is inconsistent frame to frame and session to session. The character looks slightly different every time, sometimes within the same response. For products built on character attachment, branded IP, or any kind of long-term relationship between a user and a persona, drift is not a cosmetic flaw. It is the destruction of the thing that makes the product work. Style consistency in a rig is structural. The same skeleton, the same mesh, the same materials, every time. In video, consistency is something the model tries to approximate, and fails at the edges, every time.
The fourth problem is the uncanny valley. Hyper-realistic human faces are coming, but right now they sit in the trough where they look almost right and feel deeply wrong. Stylized characters work better for mainstream consumers today, and video is structurally worse at stylization than it is at photorealism. The thing video is best at is the thing AI personas should not be doing yet.
The fifth problem is the device. Video is heavy on bandwidth and battery, and it depends on a strong connection. The moment the user's signal drops, the persona breaks. Multiplayer, shared synchronous experiences where multiple users see the same character react in the same way at the same time, is essentially impossible with streamed pixels. You cannot synchronize what you cannot lighten.
A real-time character rig system solves all of this by being a fundamentally different architecture. The character is a 3D asset that lives on the client. The server sends lightweight animation signals. Blend shapes, bone transforms, motion curves, measured in kilobytes instead of the megabytes a video stream requires. The rig runs locally, so GPU and battery cost stay bounded. Character state can update in under 100ms from live audio, emotion, or conversational context, because the work is happening on device and the server only has to send the next animation parameter. Customization, wardrobe, and collection mechanics plug directly into the rig, which turns the character itself into a monetization surface. And because the asset is engine-ready, the same character lives across apps, web, mobile, games, and spatial computing without being rebuilt for each platform.
The case for the rig path is direct. If you believe in real-time interaction at scale between users and AI personas, and the technical lift and timeline are not the deciding factor, the rig is the only realistic approach. That's before you factor in the added utility and monetization that customization unlocks.
The honest answer to "Will real-time generative video close the gap?" is partly yes and mostly no. Diffusion video latency is dropping fast, and the gap on responsiveness will narrow. The structural problems remain. There is no path to client-side rendering, so GPU costs per user per session stay expensive forever. Generative video drifts frame to frame, which is fatal for anything built on identity and attachment. Holding a specific aesthetic reliably across emotional states is still an unsolved generative problem. Latency is the surface issue. The architecture underneath is the real one.
We picked the rig path for those reasons. It's harder. The talent is scarce, the systems are specialized, and you have to ship a real-time renderer and character system across iOS, Android, Web, desktop, and game engines. We spent years building that team and that infrastructure, and we built the framework in a way that auto-generates platform wrappers so the team required to maintain it stays small. The hard part is done. What's left is the upside.
How It Actually Works
There are two models doing the work, and they sit on top of whatever LLM or stack is generating the underlying intelligence.
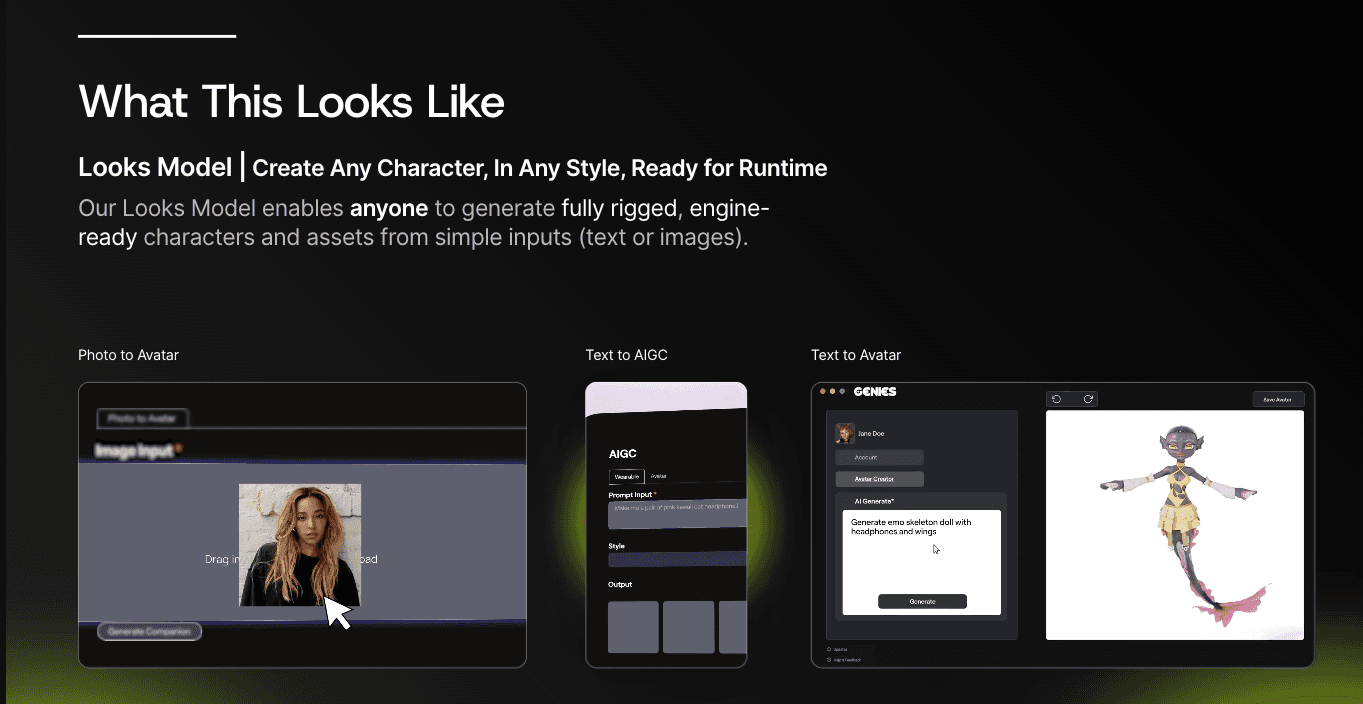
The Looks Model generates the character. Text input or a photo goes in, a fully rigged engine-ready 3D avatar comes out. Not a render, not a flat image. An actual asset with bones, blend shapes, and the metadata a runtime needs to drive it. This is how anyone, including the end user, can spin up a character on demand without a 3D artist in the loop.

The Behavior Model brings it to life. The LLM produces text and intent. The Behavior Model converts that into expressive, character-consistent motion in real time. Facial performance, gesture, posture, gaze, micro reactions. It's the layer that makes the character act, feel, and respond rather than just lip sync to a transcript. It's also the layer that does the trust work. A face that doesn't react in the right places, or reacts in the wrong ones, breaks the spell faster than a wrong answer ever will.
Both models output to a runtime we built to run on the client. Each avatar is roughly 20MB, streamed over the air with flexible caching. The rig executes on device, so GPU and battery cost stays bounded. Ten to a hundred-plus avatars can run at 120fps on a consumer phone. The character renders locally, the server just sends the animation signal, and the lightweight data model means we're moving kilobytes of blend shapes and bone transforms instead of megabytes of video frames.
The result is sub-100ms responsiveness on character state. The avatar reacts to user input, UI state, audio, emotion, and conversational context as fast as the underlying LLM can produce it. That responsiveness is what makes the face feel alive instead of canned.
What the Rig Actually Gives You

The architecture pays back across every dimension that matters for an AI persona at scale.
Responsiveness is native. The character reacts in the same frame the input arrives, because the computation is local and the asset is already loaded. Identity is on-model by construction. The character does not drift between frames, sessions, or platforms, because it is the same asset every time, driven by the same skeleton. Cost stops scaling linearly with users, because compute is offloaded to the client and the server only sends signal. Multiplayer becomes trivial, because synchronized state is cheap when you are not also synchronizing pixels. Distribution is universal, because engine-ready assets work across apps, web, mobile, games, and spatial environments without being rebuilt. Monetization is built in, because anything you can attach to a rig (wardrobe, accessories, customization, collection mechanics) becomes a commerce surface.
None of this is theoretical. The runtime ships today. The data model is animation parameters in kilobytes instead of video frames in megabytes. The unit economics are roughly 350x more efficient than video systems doing equivalent work.
Why Stylized, Not Photoreal
We make stylized characters on purpose. Hyper-realism is coming, and eventually it'll be table stakes. For the next several years, stylization is the right answer for mainstream consumers. It destigmatizes the AI persona, removes the uncanny valley, and lowers the barrier to adoption. People will hang out with a stylized character. They will not hang out with a slightly wrong-looking simulation of a real human.
Stylization also makes trust easier to earn. A stylized character is honest about what it is. There's no pretense that you're talking to a person, which means the relationship gets to be its own thing rather than a failed imitation of a human one. Users relax. They engage longer. They come back.
Stylization is a creative advantage. All characters, all styles, all use cases. A consumer companion, a brand mascot, a game NPC, an enterprise sales agent, a fitness coach, a teacher. The same rig system handles all of them, and the visual range is wider than what photoreal allows.
Who's Building With it
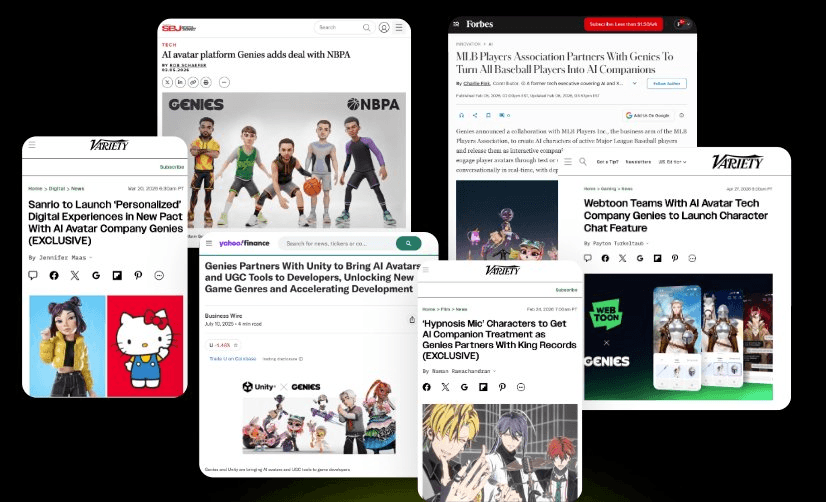
The thesis isn't theoretical. Some of the biggest IP holders in entertainment and sports have already chosen this layer to bring their characters and talent to life.
MLB Players Inc. is turning the league's biggest stars into interactive AI characters so fans can build a connection with players that doesn't end when the game does. The NBPA is doing the same for basketball around authentic player IP. Sanrio is bringing characters like Gudetama into personalized interactive experiences, with the brand's full creative oversight intact. King Records, Kodansha's anime and music subsidiary, is reimagining the 21 core characters of Hypnosis Mic as interactive AI characters built and supervised by human creators. WEBTOON Entertainment is giving its creators an opt-in path to extend their characters off the page into 3D interactive experiences fans can talk to, collect from, and unlock more story context.
Different categories, different fanbases, different aesthetics. The same layer underneath.
What This Unlocks

AI personas are the new interface. Every digital experience that currently routes through a chat input is going to route through a character instead, because characters carry presence, personality, and emotional bandwidth that text and voice cannot. That bandwidth is what produces trust, and trust is what produces engagement, retention, and ultimately the kind of relationship that turns a feature into a habit.
The market for owning AI personas in entertainment alone is over $100B. The same layer applied across consumer, enterprise, gaming, and creator categories is meaningfully larger. AI companions, AI tutors, AI shopping assistants, AI brand representatives, AI NPCs, AI knowledge agents, AI sales agents, AI customer support, AI training agents. Every one of these is an AI persona looking for a face.
We built the face. The rig system runs at scale, the models generate and animate characters on demand, the runtime ships everywhere, and the unit economics are roughly 350x more efficient than video systems doing the same job.
AI needed a face and a persona. This is it.
Giving your AI an identity, or want to see how the character system works from a more technical level? Get in touch.